
Aurora : Un Nouveau Modèle de Fondation de l’Atmosphère
Les modèles de fondation en apprentissage profond (Deep Learning) ont révolutionné, ces dernières années, divers domaines scientifiques tels que la prédiction de la structure des protéines, la découverte de médicaments, la vision par ordinateur ou encore le traitement du langage naturel. Ces modèles constituent des technologies capables d’accomplir un large éventail de tâches générales et se distinguent des systèmes d’Intelligence Artificielle (IA) restreints, qui se concentrent sur une tâche spécifique ou limitée.
Les modèles de fondation reposent sur deux grandes phases :
- un pré-entraînement, où un réseau neuronal apprend à capturer des configurations et des structures complexes à partir de vastes ensembles de données diversifiées ;
- et un fine-tuning, qui permet au modèle d’exploiter au mieux les représentations acquises pour les appliquer, avec de très bons résultats, à de nouvelles tâches sur lesquelles il dispose de données d’entraînement limitées.
Plusieurs initiatives ont déjà vu le jour visant l’application de l’IA à la modélisation du temps ou du climat : Pangu-weather et son prolongement Zhiji, développés par Huawei, GraphCast mis en place par Google, FourCastNet, développé par Nvidia, ou encore une collaboration entre IBM et la NASA annoncée fin 2023.
Le système Terre constitue un réseau complexe et interconnecté de sous-systèmes (atmosphère, océans, terres, glace) en étroite interaction. Dans un contexte de changement climatique où la compréhension précise de ces sous-systèmes prend une importance croissante, les modèles de fondation pourraient profondément transformer notre capacité à modéliser ceux-ci et la Terre dans son ensemble. D’autant plus que l’atmosphère, sur laquelle on dispose de très nombreuses données, est particulièrement propice au pré-entraînement de ce type de modèle.
C’est sur la base de ces constats que l’équipe de recherche de Microsoft a développé Aurora, un modèle de fondation à grande échelle pour l’atmosphère. Aurora génère des prévisions de pollution de l’air à 5 jours et des prévisions météorologiques mondiales à 10 jours, et ce à résolution spatiale élevée (jusqu’à 0,4° et 0,1°, respectivement ; 0,1° ~ 11 km à l’équateur), surpassant les outils de simulation classiques et les autres approches d’apprentissage profond actuelles. En somme, c’est un modèle composé de 1,3 milliard de paramètres pré-entraîné sur plus d’un million d’heures de données atmosphériques diversifiées, principalement constituées de simulations de modèles météorologiques et climatiques.
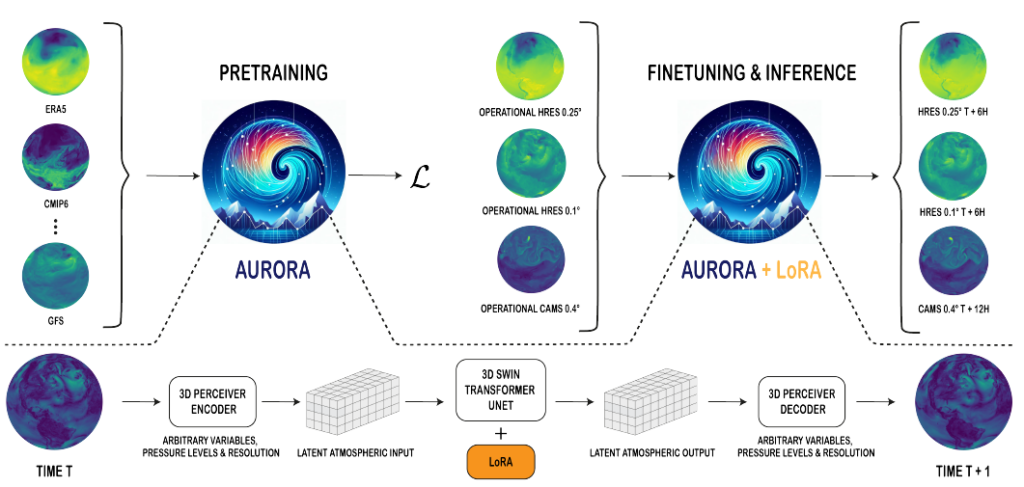
Aurora est capable d’intégrer et de réaliser des prédictions pour une grande variété de variables de surface et météorologiques. Plus précisément, le modèle se compose de trois parties :
un encodeur qui convertit les entrées hétérogènes en une représentation standard 3D de l’atmosphère ;
un processeur qui fait évoluer cette représentation dans le temps ;
un décodeur qui traduit la représentation 3D en prédictions spécifiques.
D’autre part, Aurora est pré-entraîné sur un vaste ensemble de données météorologiques et climatiques pour acquérir une représentation générale des différentes dynamiques atmosphériques. A la différence des autres modèles de fondation de l’atmosphère entraînés sur un seul ensemble de données, les données alimentant Aurora proviennent de six ensembles différents : ERA5 (European Centre for Medium-Range Weather Forecasts (ECMWF) Reanalysis v5), CMCC (du Centre euro-Méditerranéen sur le Changement Climatique), IFS-HR (de l’ECMWF), HRES Forecasts (de l’ECMWF), GFS Analysis (du National Centers for Environmental Prediction (NCEP)) et GFS Forecasts (du NCEP). Ce pré-entraînement vise à minimiser l’Erreur Absolue Moyenne (MAE – Mean Absolute Error) à l’étape suivante avec un temps de prédiction de 6 heures, représentant, in fine, une période d’entraînement totale de deux semaines et demie sur 32 unités de traitement distinctes.
Une fois pré-entraîné, Aurora est ensuite affiné pour de nouvelles tâches de prédiction atmosphérique. Concernant les prévisions de pollution, ce sont les données CAMS (Copernicus Atmosphere Monitoring Service) d’octobre 2017 à mai 2022 qui ont été utilisées pour le « fine-tuning », ainsi que celle de mai 2022 à novembre 2022 pour la phase de test. Les chercheurs de Microsoft ont également incorporé les données de réanalyse CAMS de janvier 2003 à décembre 2021 pour améliorer l’apprentissage des dynamiques des polluants.
Pour ce qui est de la prévision météorologique, Microsoft a fait le choix d’une résolution de sortie à 0,1° en raison de son importance opérationnelle. Pour ce faire, Aurora a été pré-entraîné sur des données d’entrée à 0,25° de résolution, pour être ensuite affiné sur un corpus plus petit de données à 0,1° permettant des prévisions à haute résolution.
Pour des temps de prévision allant jusqu’à 15 jours, le système de prévision intégré (IFS – Integrated Forecasting System) du Centre Européen pour les Prévisions Météorologiques à Moyen Terme (CEPMMT) est une référence et le système de prévision numérique le plus avancé. Cependant, ce système fonctionne à un coût computationnel considérable : produire une prévision à 10 jours prend environ 65 minutes sur un cluster de 352 processeurs, ce qui correspond à environ 5720 secondes par heure de temps de prévision. En comparaison, Aurora peut réaliser de telles prédictions en environ 1,1 seconde par heure de temps de prévision sur un seul processeur, offrant ainsi un gain de vitesse multiplié par environ 5000 par rapport à l’IFS.
Dans le but de valider les avantages du perfectionnement d’un modèle pré-entraîné sur plusieurs ensembles de données, Aurora a été comparé à GraphCast, un modèle de prévision uniquement pré-entraîné sur le jeu de données ERA5 et actuellement considéré comme le modèle d’IA le plus performant à 0,25° et pour des échéances allant jusqu’à 5 jours. Ainsi, les calculs de MAE et d’Erreur Quadratique Moyenne (RMSE – Root Mean Squared Error) montrent qu’Aurora surpasserait les performances de l’IFS et de GraphCast sur plus de 91% des cibles, que ce soit par rapport aux analyses, aux observations des stations météorologiques ou aux valeurs extrêmes. En effet, un exemple notable est la tempête Ciarán, qui avait traversé l’Europe du 29 octobre 2023 au 04 novembre 2023. Étant un événement météorologique exceptionnel de par ses caractéristiques atypiques (en particulier la vitesse maximale des vents à 10 mètres), Ciarán avait notamment mis en difficulté et, in fine, révélé les limites des modèles de prévisions météorologiques plus classiques sur la prédiction de la puissance des vents de cette tempête. Simulées sur les mêmes conditions de cette période, Aurora s’est révélé être le seul modèle à pouvoir prédire avec précision l’augmentation brutale de la vitesse maximale du vent de la tempête Ciarán du 2 novembre 2023.
Un aspect clé du paradigme des modèles de fondation est que leur performance s’accroît de façon significative et prévisible avec la taille des données et du modèle, ce que l’équipe de Microsoft a, pour la première fois, montré dans le domaine de la prévision météorologique comme cela l’avait été auparavant dans celui de la vision par ordinateur ou du traitement du langage naturel. Globalement, ces résultats montrent que l’utilisation d’un groupe hétérogène de données météorologiques et climatiques améliore les performances de prévision. Il en est de même également pour les variables atmosphériques en général. En effet, d’après les observations des développeurs d’Aurora, les performances de validation des différents modèles de prédiction s’amélioraient d’environ 5 % pour chaque doublement du nombre de paramètres.
Les chercheurs de Microsoft notent également que, dans le cas particulier de la modélisation météorologique, l’entraînement est généralement limité par le chargement des données plutôt que par le modèle, car un seul point de données représente généralement plusieurs centaines de mégaoctets (Mo) de données. Par conséquent, les modèles 10 fois plus petits ne peuvent pas nécessairement traiter 10 fois plus d’entités dans le même laps de temps. Ce constat favoriserait donc l’utilisation de modèles plus grands et indiquerait que l’entraînement de grands modèles n’est pas aussi coûteux qu’il n’y paraît initialement.
Aussi, bien qu’Aurora introduise de nombreuses nouvelles capacités, il reste encore beaucoup de marges d’amélioration sur plusieurs axes.
D’une part, actuellement, le modèle ne peut générer que des prévisions déterministes. Or, un traitement probabiliste serait particulièrement important pour des variables telles que les précipitations.
D’autre part, en termes de données d’entrée, bien qu’Aurora repousse les limites de la diversité de ces dernières, il n’a été entraîné que sur des ensembles de données mondiaux. Avec de nombreuses banques de données locales à haute résolution telles que HRRR (High-Resolution Rapid Refresh) et CONUS404 (Four-kilometer long-term regional hydroclimate reanalysis over the conterminous United States (CONUS)), exploiter cette nouvelle échelle spatiale pourrait s’avérer pertinent pour combler les possibles manques de données. De même, en tirant parti des connaissances acquises à partir des régions riches en données, les modèles de fondation pourraient permettre des prévisions précises même dans les zones où les données d’observation sont limitées. Néanmoins, malgré de nombreux tests effectués, la véracité de telles prédictions effectuées par Aurora reste encore à être confirmée à l’avenir.